goby指纹规则提取
goby是一款客户端的资产收集软件,其中最重要的就是其中的指纹收集规则啦,goby刚出来时候简单分析过一会,这个周末灵感突发,熬了个夜,把规则提取出来了,虽然提取的方法不太完美。
YARA规则提取
早先下载的goby是1.4.76版本,看了看目录内的资源文件,用16进制编辑器人肉翻了翻资源文件,想找找有意思的东西,然后看到crules这个文件
里面的这些数据可能是fofa的指纹
看这个文件的文件头
是YARA格式的,搜索了一番,知道YARA格式是为了检测webshell,病毒之类的文件格式,现在用在了指纹识别上,也挺厉害的。
但是下了好几个YARA的程序,都说识别YARA版本不正确,YARA!没见过,可能是作者根据YARA的格式定义自己重新写的引擎?
这个时候只能通过字节码自己做解析,我发现了指纹开始的标志是b'\x64\x65\x66\x61\x75\x6C\x74\x00',结束的标志是\x00\x00\x66\x6F\x65\x79\x65\x00,通过这个将全部的指纹提取出来了。
接下来就是分离每个指纹,因为不想去了解yara编译的一些规则,我就对着hex编辑器,一个字节一个字节的分析,探索每个字节的意义 - =
提取第一版规则
我发现了很多文字的分割符号都是\x00,然后一些规则的分割符号是\x00\x00\x00\x00\x73\x00,所以简单写了一个代码,来分割
sep = b'\x00'
s = data.split(b'\x00\x00\x00\x00\x73\x00')
all = []
for item in s:
ff = item.split(sep)
ss = []
for i in ff:
text = i.decode("utf-8", errors="ignore")
ss.append(text)
print(ss)
all.append(str(ss))
with open("fofa.txt", 'w') as f:
f.write('\n'.join(all))分割完成后就是这个样子
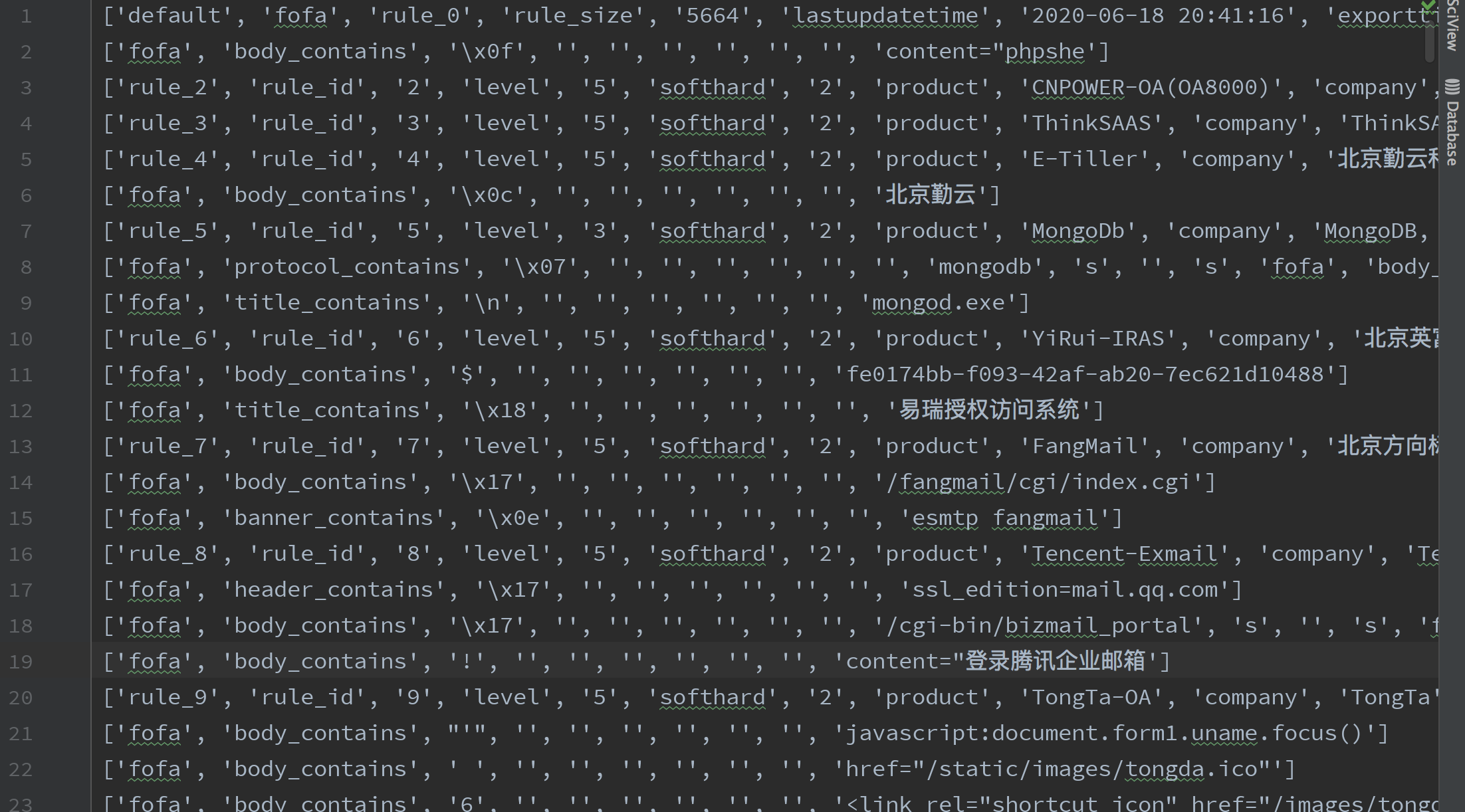
去除一下空行

中间会看到还有一些杂质,刚开始我还不知道是什么意思,后面才明白。
这样分割一下,怎么分离的规则就明白了。
每个规则的开头,都是rule_数字,后面会跟一些字段,rule_id,level,softhard等等,这些字段结束都是用\x00
后面规则的匹配,都是fofa+匹配操作,统计了一下,这种操作符有
{'port_contains', 'cert_contains', 'body_contains', 'server', 'type_contains', 'title', 'protocol_contains', 'banner_contains', 'header_contains', 'server_contains', 'title_contains'}意思也很简单,就是判断port,cert,body包含的内容,包含了就说明命中这个规则。
之后后面有一个字节代表字节长度,即是后面内容的长度。同时\x00\x00\x00\x00\x73\x00字节代表的是每个规则都是或的关系,如果是与的关系,就只有一个\x00来分割。
提取第二版规则
有了上面的经验,每个字节每个字节的读入,按照上面规则识别就行了,但代码有点难写。。我用了一个取巧的办法,通过每个规则都有的rule_id来分割每个字符,然后再用\x00来分割每个,前面几个字段描述字段都是可以确定的,后面的fofa匹配字段,再根据\x00\x00\x00\x00\x73\x00来分割。
提取代码如下
datas = data.split(b"rule_id")[1:]
sep = b"\x00"
options_set = set()
for item in datas:
ff = item.split(sep)
# print(ff)
rule_id = ff[1].decode()
level = ff[3].decode()
softhard = ff[5].decode()
product = ff[7].decode()
company = ff[9].decode()
category = ff[11].decode()
parent_category = ff[13].decode()
# print(rule_id, level, softhard, product, company, category, parent_category)
dd = {
"rule_id": rule_id,
"level": level,
"softhard": softhard,
"product": product,
"company": company,
"category": category,
"parent_category": parent_category,
"rules": []
}
bb = b'\x00'.join(ff[14:])
s = bb.split(b'\x00\x00\x00\x00\x73\x00')
_rr2 = []
for rr in s:
_rules = []
if not rr.startswith(b'fofa'):
continue
index = 0
while index < len(rr):
prefixx = b"fofa\x00"
try:
start = rr.index(prefixx, index) + len(prefixx)
except:
break
end = rr.index(b'\x00', start)
match_way = rr[start:end].decode()
# print("match_way", match_way)
_length = rr[end + 1]
content = rr[end + 9:end + 9 + _length]
index += end + 9 + _length
# _rules.append(match_way + ":" + content.decode('utf-8', errors="ignore"))
_rules.append(
{
"match": match_way,
"content": content.decode('utf-8', errors="ignore")
}
)
_rr2.append(_rules)
dd["rules"] = _rr2
results.append(dd)
with open("fofa.json", "w") as f:
import json
json.dump(results, f, ensure_ascii=False)最后生成一个json文件基本上提取了所有的规则,识别规则也处理与,或的关系,rules字段是一个list,里面的内容也是list。rules list的内容都是或关系,里面的每个list都是与关系。
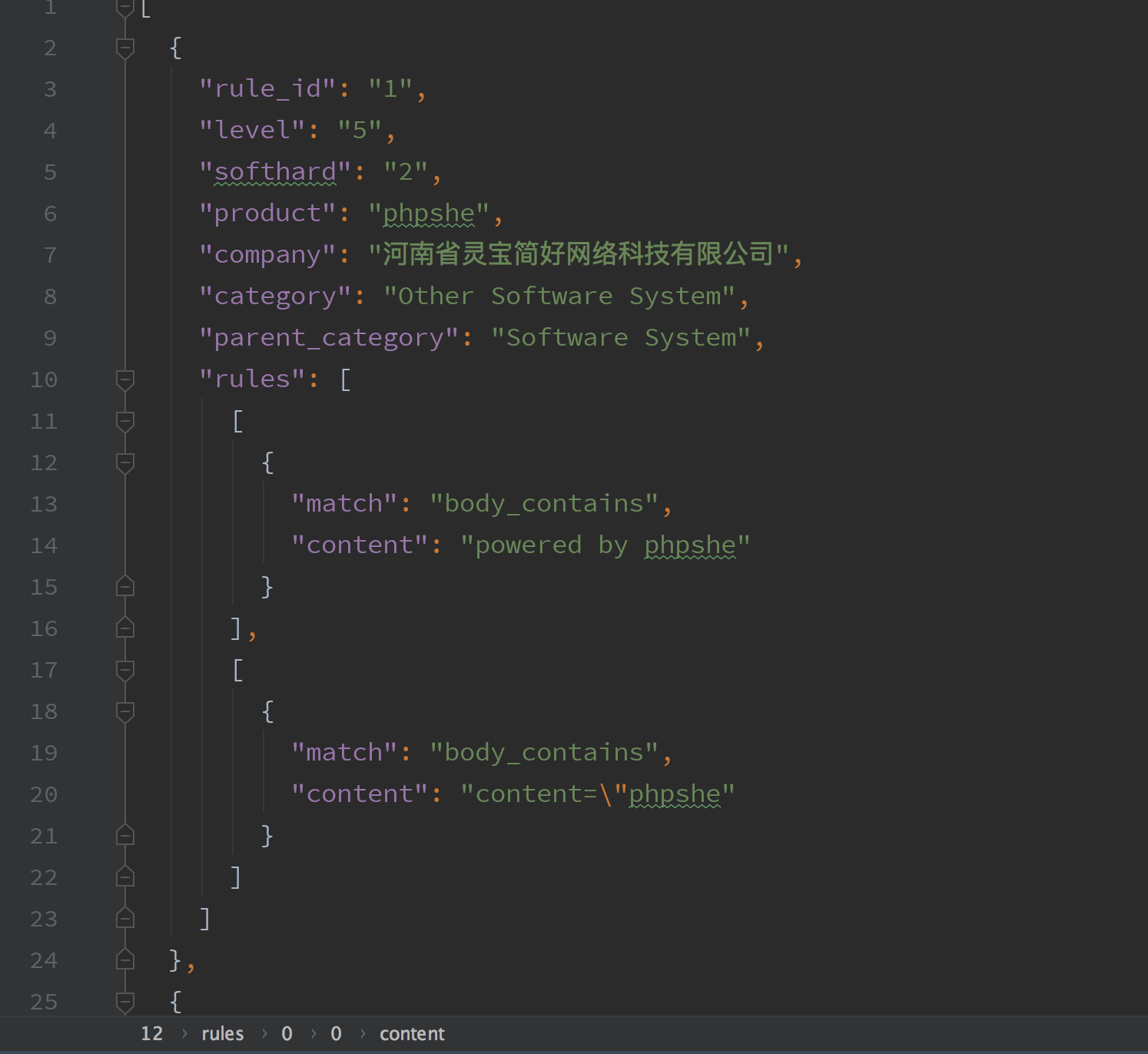
CRULES提取
在一开始的1.4.76版本,还可以找到CRULES,到了后面的找了一个最新版1.7.192,找不到了。为什么找最新版呢,因为发现最新版说又新增了2000条规则。
找了一通没有发现,那它藏哪了?
于是翻了翻它的二进制文件,找到这个github.com/rakyll/statik/fs
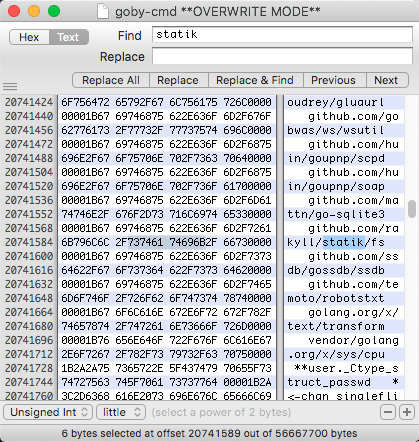
小tips:golang在默认编译的时候会存一些本地的信息,包括使用的库,一些文件目录等等
它是一个可以将静态资源文件打包进go程序的一个库,翻了下源码,原理就是生成zip二进制字节,内嵌入go源码中。
既然是zip,那肯定在二进制里面就能找到它的特征了,我先翻了翻同样是是用statik库的amass程序,一番对比发现zip文件的开头有特征的 504B0304 14000800 0800
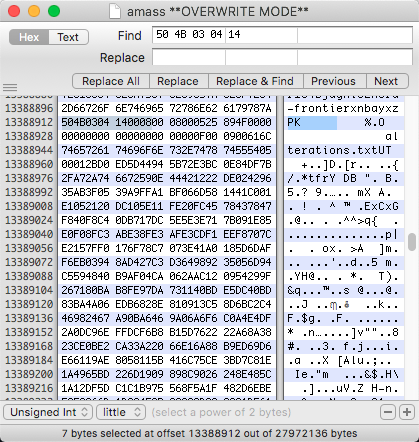
也找到了结尾的特征504B0506 00000000 2900,将这两段一前一后复制全部字节,保存为zip,也可以直接解压。
同样的道理,从goby搜索特征
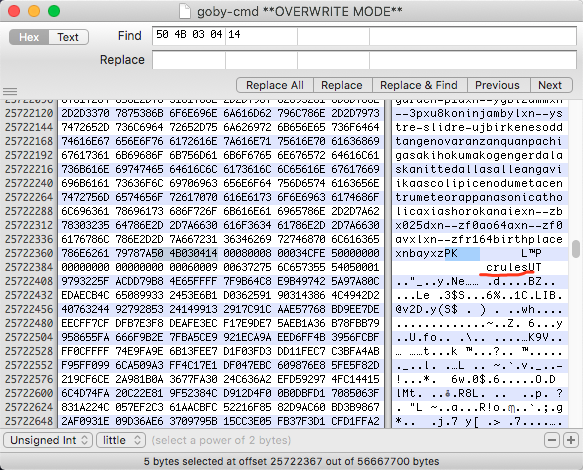
一眼就看到了熟悉的crules,哈哈,此时心里美滋滋,于是熟练的和上面步骤一样,复制粘贴解压,发现只有跟amass一样的解压文件,一模一样,验证了goby使用了amass,因为amass也是go写的,调用比较方便吧。
问题还没结束,为什么解压文件里面没有找到crules呢。
最后我觉得,应该是找到zip位置错了,开头是对的,结尾的位置找错了。那如何找对zip正确的结尾位置呢。。
我又写了一个文件,从开头的字节不断+1,然后用python的zip模块去尝试解压。
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
# @Time : 2020/9/6 1:18 PM
# @Author : w8ay
# @File : statik程序分离.py
import zipfile
from io import BytesIO
filename = "/Users/boyhack/tools/goby-darwin-x64-1.7.192/golib-mac/goby-cmd"
with open(filename, 'rb') as stream:
data = stream.read()
start = data.find(b'\x50\x4B\x03\x04\x14\x00\x08\x00\x08\x00')
end = start + 1200
while True:
fenli = data[start:end]
try:
fio = BytesIO(fenli)
f = zipfile.ZipFile(file=fio)
print(fenli[:100])
print(fenli[-10:])
print(len(fenli) // 1024)
print(f.namelist())
break
except zipfile.BadZipFile:
end += 1
with open("test.zip", 'wb') as f:
f.write(fenli)程序运行了几分钟,最后成功找到了crules!
我的思路没问题,哈哈哈哈,可能crules的zip和amass的不在一起,一开始我搜索把他们弄在一起,最后crules没出来。
crules提取出来,按照上面的程序提取成json文件,完工~